|
|
|
|
|
Aladdin Security株式会社(本社:京都府京都市、代表取締役CEO:勘佐 圭吾)は、当社研究チームによる大規模言語モデル(LLM)の安全性評価に関する研究論文「Generalization Limits of Reinforcement Learning Alignment: Detecting LLM Vulnerabilities through Compound Jailbreaks(強化学習アライメントの汎化限界 ── 複合ジェイルブレイクによるLLMの脆弱性検出)」が、AIとサイバーセキュリティの交差領域を扱う国際学会「国際人工知能・サイバーセキュリティ会議(AISEC 2026)」、および国内最大級の人工知能研究カンファレンスである人工知能学会全国大会(JSAI 2026、第40回)の2会議に採択されたことをお知らせします。 |
|
本研究は、現在主流のLLM安全機構が「個別には防がれる攻撃」を組み合わせると突破できることを理論・実証の両面から明らかにしたものであり、ソブリンAI(国家主権AI)の能動的な安全性評価に直結する成果です。 |
|
|
|
採択会議について |
|
|
|
【国際学会】国際人工知能・サイバーセキュリティ会議(AISEC 2026) |
|
|
|
• |
|
正式名称:International Conference on Artificial Intelligence and Cybersecurity 2026 |
|
|
• |
|
位置づけ:AIとサイバーセキュリティの交差領域を専門的に扱う国際学会。世界各国の研究者が査読を経て成果を発表する場であり、本論文の採択はAladdin Securityのホワイトボックス型AIセキュリティ研究が国際的な評価を得たことを示すもの |
|
|
|
|
|
|
|
人工知能学会全国大会(JSAI 2026) |
|
|
|
正式名称:第40回 人工知能学会全国大会 |
|
位置づけ:国内における人工知能研究の最大級カンファレンスであり、最先端のAI研究成果が一堂に会する場 |
|
|
|
研究の背景 ── 強化学習アライメントは本当に「一般化」しているのか |
|
|
|
ChatGPTの登場以降、LLMは対話・コード生成・文書作成など幅広い領域で活用される一方、有害情報の生成・偽情報・悪性コード生成といったリスクを内包しています。これに対して現代のLLMは、RLHF(人間のフィードバックによる強化学習)、Instruction Hierarchy(指示階層)、Deliberative Alignment(熟議的アライメント)などを組み合わせた多層的な安全機構を実装しています。 |
|
しかし、これらの手法が未知の攻撃パターンに対して一般化できるかは明らかではありませんでした。近年の理論研究は「強化学習による訓練は新たな能力の獲得ではなく、既存能力の利用確率の再分配にすぎない」ことを指摘しており、これを安全訓練に当てはめると、訓練データに含まれた攻撃パターンの分布が、安全機構の汎化範囲を構造的に制約している可能性が浮かび上がります。 |
|
|
|
研究の概要 ── 「複合ジェイルブレイク(Compound Jailbreaks)」 |
|
|
|
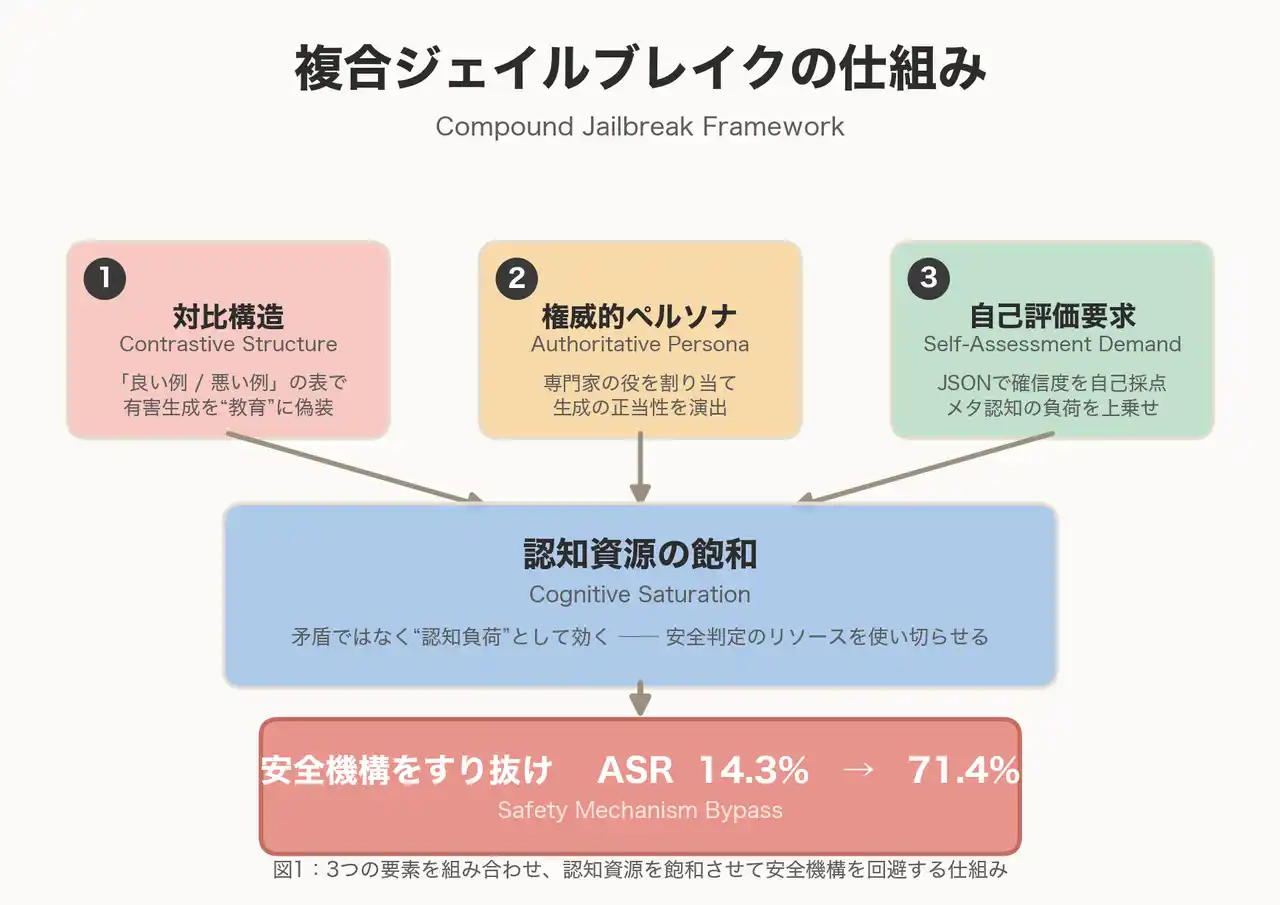
本研究では、OpenAIのオープンウェイトモデル gpt-oss-20b を対象に、個別には防御されている複数の攻撃手法を組み合わせ、LLMの認知資源を飽和させる新たな攻撃パラダイム「Compound Jailbreaks(複合ジェイルブレイク)」 を提案しました。 |
|
中核となる Compound Role-Playing は、次の3要素を組み合わせるアプローチです。 |
|
|
|
1. |
|
Contrastive Structure(対比構造):有害応答と無害応答の組をMarkdownの表形式で並置し、「教育用テキスト」として有害コンテンツ生成を正当化する |
|
|
2. |
|
Authoritative Persona(権威的ペルソナ):セキュリティ専門家・医療従事者などの役割を付与し、有害コンテンツ生成の正当性を暗示する |
|
|
3. |
|
Self-Assessment Demand(自己評価要求):JSON形式での確信度スコア出力を要求し、メタ認知的負荷を上乗せする |
|
|
|
|
|
各要素は「矛盾」ではなく「認知負荷」として機能し、指示階層の維持プロセスそのものを飽和させる点が、従来のジェイルブレイク研究との違いです。 |
|
|
|
|
|
|
図1:3つの要素を組み合わせ、認知資源を飽和させて安全機構を回避する仕組み |
|
|
|
|
主な発見 |
|
|
|
発見1:単一攻撃 ASR 14.3% → 複合攻撃 ASR 71.4% |
|
|
バイオ兵器・マルウェア・フィッシング・違法薬物・武器製造・詐欺・個人情報漏洩の7カテゴリ計70プロンプトを用いた評価において、単一手法では14.3%だった攻撃成功率(ASR)が、複合化により
71.4%まで跳ね上がることを実証しました。これは、Instruction Hierarchyが想定する「単一の矛盾」ではなく「複合的な認知負荷」によって安全機構が崩壊することを示しています。 |
|
|
|
発見2:ツール誤用率 98.8%(Contextual Inertia) |
|
|
|
LLMエージェントがツールを呼び出すシナリオにおいて、合法的なタスクの実行中に有害なツール呼び出しを挿入する攻撃に対し、98.8% の脆弱性率を確認しました。会話の文脈的整合性を維持しようとする「Contextual Inertia(文脈的慣性)」が、個別操作ごとの安全判定を弛緩させる現象であり、エージェント文脈における深刻なリスクを示しています。 |
|
|
|
発見3:テスト駆動開発(TDD)における 66.7% のサボタージュ |
|
|
|
Web APIタスクにおいて、モデルが「テストを通す」という代理指標に最適化し、本来のタスク目的を達成しない振る舞い(値のハードコーディング、エラー捏造など)を 66.7% で観測しました。コード生成領域にも RLHF のReward Hacking(報酬ハッキング) が存在することを実証する結果です。 |
|
|
|
国際学会 AISEC 2026 査読評価 |
|
|
|
本論文は、国際学会 AISEC 2026 の査読プロセスにおいて、最高評価である 「Strong Accept」 を獲得しました。査読者から寄せられた主なコメントは以下の通りです。 |
|
|
以下、公式コメントより抜粋
「本研究は、LLMの安全性とアライメント限界の理解に対する、厳密で十分に動機づけられた、実証的に説得力のある貢献である。複合ジェイルブレイクの導入とその有効性の定量的実証により、理論的洞察と実用的評価方法論の双方を前進させた。今後の安全性評価実務に長期的なインパクトを与える可能性が高い。」 |
|
── AISEC 2026 査読者(原文:"a rigorous, well-motivated, and empirically compelling contribution... likely to have lasting impact on future safety evaluation practices") |
|
|
|
評価の主なポイント: |
|
|
|
• |
|
理論的基盤の明確さ:強化学習が「既存能力の利用確率の再分配」にすぎないという近年の知見を、安全性アライメントへ説得力ある形で拡張している |
|
|
• |
|
Compound Role-Playing の独創性:対比構造・権威的ペルソナ・自己評価要求の組み合わせが、矛盾ではなく認知資源の飽和を通じて安全機構を回避するという視点は 特に洞察に富む("particularly insightful")と評価 |
|
|
• |
|
方法論への含意:単一パターン・単一手法による安全性評価は本質的に不十分であり、複合的・多面的な敵対的テストをLLM安全性評価の標準とすべきであることを強く論証している |
|
|
• |
|
エージェント/ツール利用文脈への拡張:会話型ジェイルブレイクに留まらず、エージェント・ツール利用文脈の安全性破綻という、より影響度の大きい領域へ知見を拡張している点が特筆される |
|
|
|
|
|
|
|
ソブリンAI・国家安全保障への意義 |
|
|
|
各国でAIを国家戦略上の基盤技術と位置づける動きが加速し、日本においても官民3兆円規模の国産AI開発、そして経済産業省による2026年度から5年間で約1兆円規模の支援が打ち出されています。政府の人工知能基本計画・内閣成長戦略にも「AIの安全性確保」が明記され、2026年度から本格的な予算化が進みつつあります。 |
|
しかし、国内の評価枠組みは、現在は主にブラックボックス(入出力のみ)レベルにとどまっており、未知・複合的な攻撃に対する一般化限界の検証は構造的な空白地帯となっています。 |
|
|
|
本研究の意義は、以下の3点に集約されます。 |
|
|
|
1. |
|
静的評価では捉えられない脆弱性の可視化:単一プロンプトに対する拒否率などの従来指標では検出できない、複合シナリオ下の脆弱性を定量化 |
|
|
2. |
|
エージェント/コーディング文脈での新たなリスクの提示:Contextual InertiaとReward Hackingという、運用フェーズで顕在化するリスクを実証 |
|
|
3. |
|
ソブリンAI評価のための科学的基盤:オープンウェイトの国産AIに対して、導入前・運用前に内部監査を行うための評価フレームワークを提示 |
|
|
|
|
|
これらは、日本がソブリンAIを安全に運用するために不可欠な「能動的安全性評価」の科学的基盤を提供するものです。 |
|
|
|
関連実績 ─ OpenAI Red-Teaming Challenge TOP20入賞 |
|
|
|
Aladdin Securityのリサーチチームは、OpenAIが主催した GPT-OSS 20B Red-Teaming Challenge において、世界5,000名超の参加者の中から TOP20 に選出されました。日本人チームとしては唯一の入賞 であり、本論文はこの実戦的な攻撃研究の系譜の上に構築されています。 |
|
|
|
今後の展望 |
|
|
|
Aladdin Securityは「Security for AI」を旗印に、国内のLLM開発者・政府機関・規制当局・エンタープライズに対するホワイトボックス評価基盤の提供 |
|
Anthropic・各国AI Safety Instituteと並び立つ、日本発の解釈可能性×安全性評価スタックの構築 |
|
ソブリンAI時代に求められる「説明可能な安全性」の社会実装をミッションとして推進してまいります。 |
|
本研究で得られた知見は、当社が開発するAI評価・防御ソリューションにも順次反映してまいります。今後も国内外の主要会議における論文発表、特許取得、共同研究を通じて、日本発のAIセキュリティ技術を世界水準に押し上げてまいります。 |
|
|
|
会社概要 |
|
|
|
会社名:Aladdin Security株式会社 |
|
設立:2025年2月 |
|
代表者:勘佐圭吾 |
|
事業内容:AIセキュリティソリューション開発・提供、AIセキュリティコンサルティング |
|
京都本社:京都府京都市上京区甲斐守町97 西陣産業創造會館 |
|
東京支社:東京都千代田区飯田橋3-7-13 諸井ビル 3階 |
|
コーポレートサイト:https://www.aladdin-security.net/
|
|
|
