|
|
|
|
|
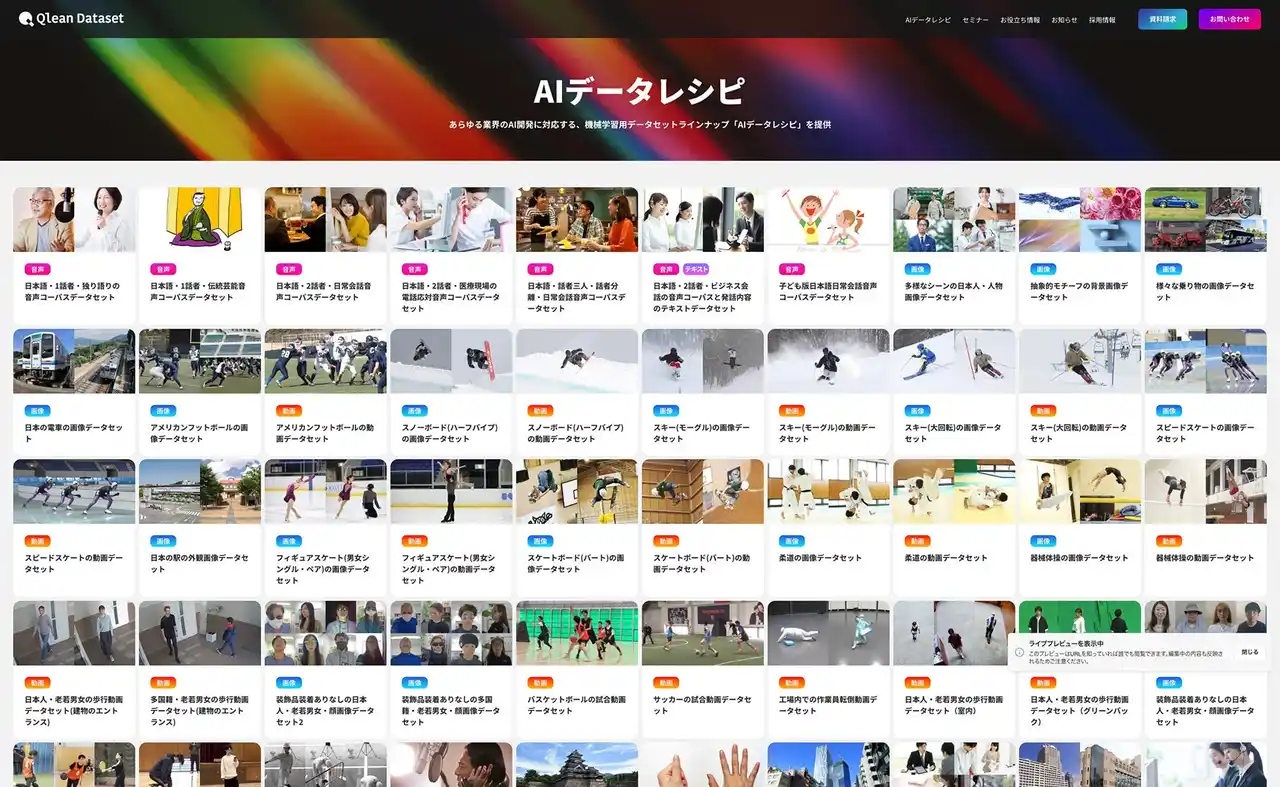
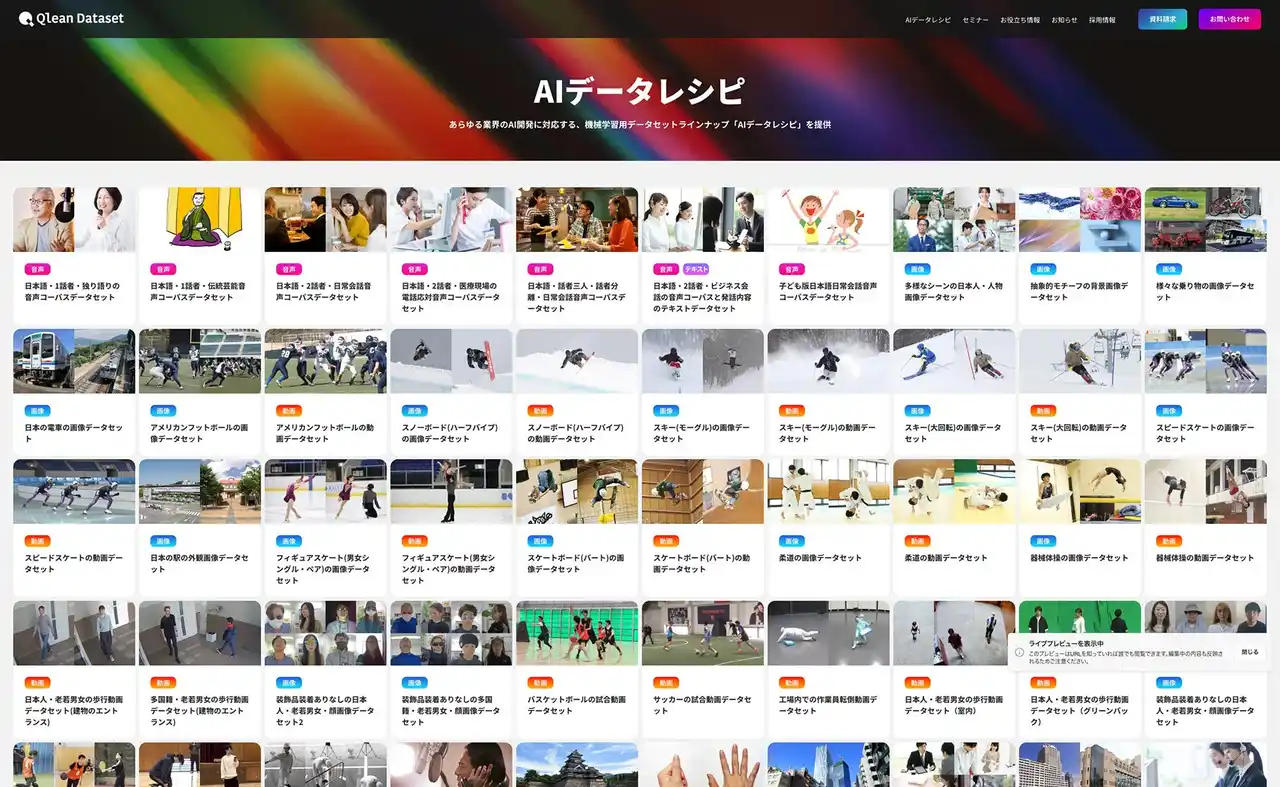
Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、就職活動における人物の動的な特徴抽出や、高度なマルチモーダル解析モデルの学習に最適化された、「日本人・新卒採用選考の自己PR動画データセット」の提供を開始します。 |
|
|
|
本データセットは、オンライン面接や動画選考が普及する現代の採用シーンを忠実に再現した動画データとメタ情報で構成されています。新卒就職活動生を想定した若年層の日本人が、カメラに向かって自身の強みやエピソードを話す様子を収録。オンライン面接で一般的となっている正面からのバストアップアングルを採用しており、実際の選考環境に近い視覚・音声情報を備えています。 |
|
収録内容は、話し手の感情や抑揚が反映されやすいフリートーク形式と、発話内容が固定された指定台本の読み上げ形式の両方を含みました。これにより、音声認識(ASR)の精度向上だけでなく、非言語情報である視線や表情の変化、発話の流暢さといった、定性的なコミュニケーション要素の解析に適した構成となっています。また、本データセットは独自のモデルアサインによる追加収録が可能なため、特定の属性に絞った音声データの拡張や、長尺の発話データ確保など、音声・言語領域の深いニーズに合わせたカスタマイズにも柔軟に対応します。 |
|
|
|
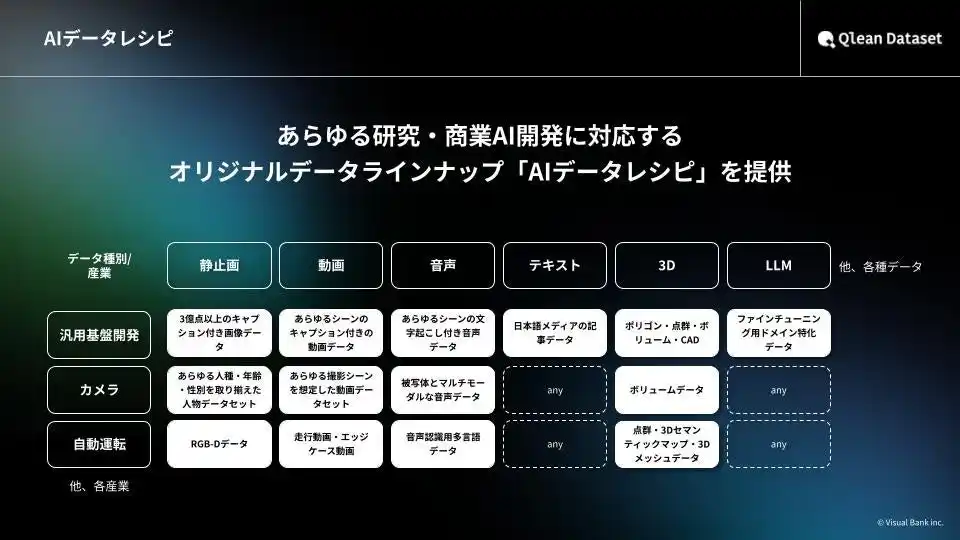
本データは、Qlean Datasetが展開するAI開発用オリジナルデータラインナップ「AIデータレシピ」の一つとして提供され、次世代の採用支援AIの実装から、選考対策などの教育・トレーニング用プロダクトの開発まで、社会実装を見据えたAIプロジェクトを強力に後押しします。Visual Bankおよびアマナイメージズは、今後も日本の多種多様なシーンを捉えた構造データの提供を通じて、人物の振る舞いを正確に理解・解析するAIの研究・開発を支援していきます。 |
|
|
|
|
|
今回提供を開始する「日本人・新卒採用選考の自己PR動画データセット」の概要 |
|
|
|
|
|
|

|
|
|
|
Sample |
|
|
|
|
|
「日本人・新卒採用選考の自己PR動画データセット」のユースケースイメージ |
|
|
|
【研究用途】 |
|
|
|
• |
|
非言語コミュニケーション解析モデルの構築 |
|
就職活動という評価対象となる場面において、緊張感や自信といった心理状態が表情、視線の動き、発話のピッチにどのような影響を与えるかを分析するマルチモーダル解析の研究に利用できます。 |
|
|
|
|
|
|
|
【産業用途】 |
|
|
|
• |
|
HRテックにおける動画選考支援アルゴリズムの開発 |
|
AIを用いた動画面接スクリーニング機能において、候補者の発話内容の書き起こしや、表情の明るさ・目線の定着度を指標化する特徴量抽出モデルの学習に利用できます。 |
|
|
• |
|
特定シチュエーションにおける音声合成(TTS)・音声変換モデルの開発 |
|
自己PRという緊張感の伴う発話環境を活かし、特定の感情や緊張度を再現する音声生成AIの学習や、特定のトーンに特化した追加収録のベースデータとして活用できます。 |
|
|
• |
|
Web会議システム向けバーチャル背景・ライティング補正の検証 |
|
オンライン面接特有のバストアップ構図における、人物の輪郭抽出(セグメンテーション)や、肌の質感を自然に補正する画質向上アルゴリズムの精度評価に利用できます。 |
|
|
|
|
|
|
|
|
|
『Qlean Dataset(キュリンデータセット)』について |
|
|
|
『Qlean Dataset』は、Visual Bank傘下の株式会社アマナイメージズが提供する商用利用可能なAI学習用データソリューションです。 |
|
画像・動画・音声・3D・テキストなど、多様な形式のデータに対応し、研究・商用いずれの用途でも安全に利用できる環境を整備しています。また、国内・海外のデータホルダーやラジオ・新聞社・通信社等のメディアとの協業を通じ、業界特化・最新トレンドに即したデータラインナップ『AIデータレシピ』を継続的に拡充しています。 |
|
Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援します。 |
|
Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
|
|
AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
『Qlean Dataset』の提供するデータセット『AIデータレシピ』の特徴 |
|
|
|
• |
|
|
• |
|
|
• |
|
カスタム撮影・収録・収集による独自データ構築にも対応 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Visual Bank株式会社 |
|
|
|
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。 |
|
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。 |
|
代表取締役CEO:永井 真之 |
|
所在地:〒107-0062 東京都港区南青山7-1-7 C-Cube南青山ビル6F |
|
Visual Bank企業URL:https://visual-bank.co.jp/
|
|
アマナイメージズ企業URL:https://amanaimages.com/about/
|
|
|
|
|
 |
|
|
|
New Multimodal Dataset: High-Stakes Self-PR Scenarios in Japanese |
|
|
|
Optimized for Affective Computing and Non-Verbal Interaction Analysis in Professional Contexts |
|
|
|
|
|
|
|
Visual Bank Inc. (Minato-ku, Tokyo; Saneyuki Nagai, CEO) is pleased to announce the release of the "Japanese Job Candidate Self-PR Video Dataset" through its AI training data solution, Qlean Dataset. Operated by its subsidiary, amanaimages Inc., this dataset is optimized for extracting dynamic human features and training advanced multimodal analysis models within the recruitment context. |
|
|
|
This dataset faithfully reproduces modern hiring scenarios, such as online interviews and video screenings, which have become industry standards. The collection features young Japanese adults-simulating new graduates-speaking about their strengths and personal experiences directly to the camera. Each video uses a front-facing, waist-up (bust-up) angle typical of online meetings, providing visual and audio data that closely mirrors real-world selection environments. |
|
The content includes two distinct formats: "free-talk," which naturally captures the speaker's emotions and intonation, and "scripted reading," where the speech content is fixed. This dual approach is designed not only to improve Automatic Speech Recognition (ASR) accuracy but also to facilitate the analysis of qualitative communication elements, such as changes in gaze, facial expressions, and speech fluency. Furthermore, as Qlean Dataset offers custom data collection through specific model assignments, the dataset can be expanded to meet deep R&D requirements, including diversifying speaker attributes or securing longer-form speech data for linguistic modeling. |
|
|
|
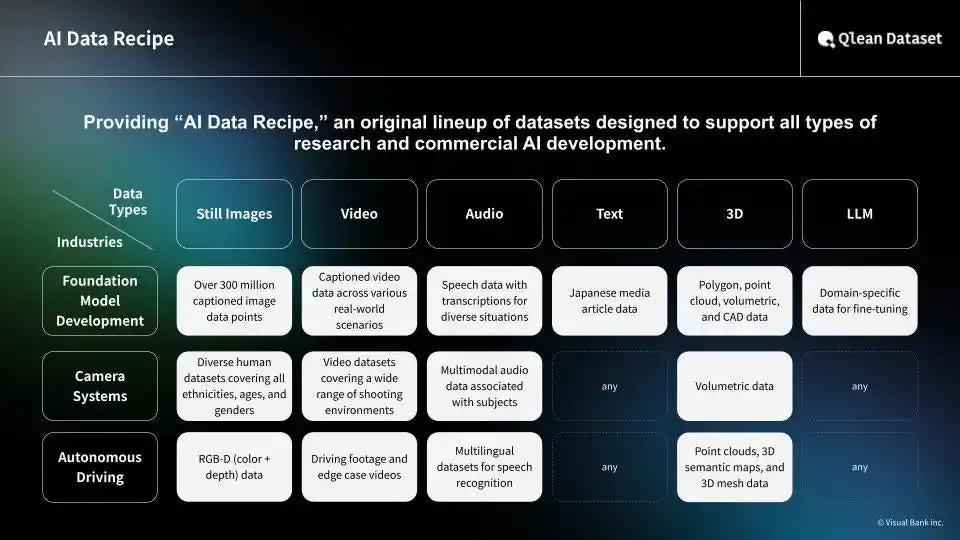
This release is part of the "AI Data Recipe," Qlean Dataset's lineup of original data solutions for AI development. It is designed to power the next generation of social implementation, ranging from automated recruitment screening to the development of educational and training products for interview preparation. Visual Bank and amanaimages remain committed to supporting the research and development of AI that can accurately understand and analyze human behavior by providing structured data that captures the diverse realities of Japanese life and society. |
|
|
|
|
|
Dataset Overview |
|
|
| Data Type: |
Video |
| Subject Attributes: |
Japanese (Young adults/prospective graduates), including gender metadata |
| Data Volume: |
5,764.40 MB |
| Quantity: |
72 clips |
| Format: |
mp4 |
| Duration: |
Approx. 1 minute per clip |
| Recording Environment: |
Angle: Frontal/Bust-up (simulating online interviews)
Variations: Free-talk format and scripted reading format |
| Metadata: |
List format providing gender and "Scripted/Non-scripted" flags |
| Sample Page: |
https://qleandataset.visual-bank.co.jp/en/lineup/ds-048 |
|
|
|
|
|
|
|
|
Use Case Examples |
|
|
|
【Research & Academia】 |
|
|
|
• |
|
Development of Non-Verbal Communication Analysis Models: Can be used for multimodal research to analyze how psychological states-such as tension or confidence-affect facial expressions, eye movement, and speech pitch in high-stakes evaluative settings like job interviews. |
|
|
|
|
|
|
|
【Industrial Applications】 |
|
|
|
• |
|
AI-Driven Video Interview Screening in HR Tech: Serves as training data for algorithms that transcribe candidate speech (ASR) or quantify features such as facial brightness and gaze stability to assist in candidate evaluation. |
|
|
• |
|
Development of TTS and Voice Conversion Models for Specific Scenarios: Utilizes the unique high-pressure environment of "Self-PR" to train generative AI in reproducing specific emotions and stress levels, or as base data for customizing vocal tones in conversational agents. |
|
|
• |
|
Validation of Virtual Backgrounds and Lighting Correction for Web Conferencing: Ideal for evaluating the accuracy of human segmentation and natural skin tone correction algorithms specifically for the bust-up framing used in professional online interactions. |
|
|
|
|
|
|
|
|
|
About Qlean Dataset |
|
|
|
Qlean Dataset is a commercially cleared AI training data solution provided by Amana Images, a subsidiary of Visual Bank Group. The platform offers diverse data formats including image, video, audio, 3D, and text, as well as a specialized AI Data Recipe lineup developed through collaborations with major media organizations and data rights holders. |
|
URL:https://qleandataset.visual-bank.co.jp/en
|
|
URL:https://qleandataset.visual-bank.co.jp/en/products/japanese-language-corpora
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
About Visual Bank Inc. |
|
|
|
Visual Bank Group is a technology company developing data infrastructure and AI solutions that support advanced AI development. The company operates THE PEN, an AI tool for manga creators, and its subsidiary, amanaimages Inc., provides commercial digital content and AI training data solutions, including Qlean Dataset. Visual Bank is also a selected participant in GENIAC, a Japanese government initiative supporting the advancement of next generation AI technologies. |
CEO: Saneyuki Nagai
Website:https://visual-bank.co.jp/en
|
|