|
|
|
|
|
本技術は、データを展開せずに圧縮状態のまま検索・推論を行う世界初のAI構造で、ホワイトペーパーを同時公開し、追試可能な形で技術を開示しています。 |
|
|
|
|
|
|
|
■ 背景
|
|
GPU依存AIの限界を突破する「第三の方式」AI検索や生成AIの多くは、GPUでの数百次元ベクトル演算を必要とし、一般環境では扱えないという課題がありました。 |
|
|
|
その結果: |
|
GPUコストが高い |
|
ベクトル展開でメモリ消費が大きい |
|
中小企業・自治体が導入しづらい |
|
|
|
といった問題が生じていました。今回公開する CompreSeed AI は、これらの課題を根本から解決する 新しい“圧縮推論方式” です。 |
|
|
|
|
|
|
|
■ データを“展開せずに”推論できるAI構造
|
|
|
|
・ 圧縮状態のまま検索・推論 |
|
・ ベクトル展開不要 |
|
・ CPUのみで大規模知識検索 |
|
・ 応答速度 0.2~0.8秒 |
|
CompreSeed AI は、意味的圧縮構造(semantic_index)を使い、データを展開せずに「直接意味検索・推論」します。これにより AI計算コストを1/50~1/70に削減 できます。 |
|
|
|
|
|
|
|
■ 実機検証:NEC製ノートPCで Wikipedia300万件を1.8GBに圧縮し高速応答
|
|
|
|
【検証環境】 |
|
PC:NEC Lavie NS150(一般家庭向けモデル) |
|
GPU:非搭載 |
|
RAM:8~16GB |
|
OS:Windows 11 |
|
実行環境:Python + Flask UI |
|
知識データ:Wikipedia 3,000,000件(圧縮後 1.8GB) |
|
|
|
【結果】 |
|
応答速度:0.2~0.8秒 |
|
メモリ使用量:2~3GB |
|
安定稼働:長時間でも負荷が低い |
|
|
|
|
|
|
|
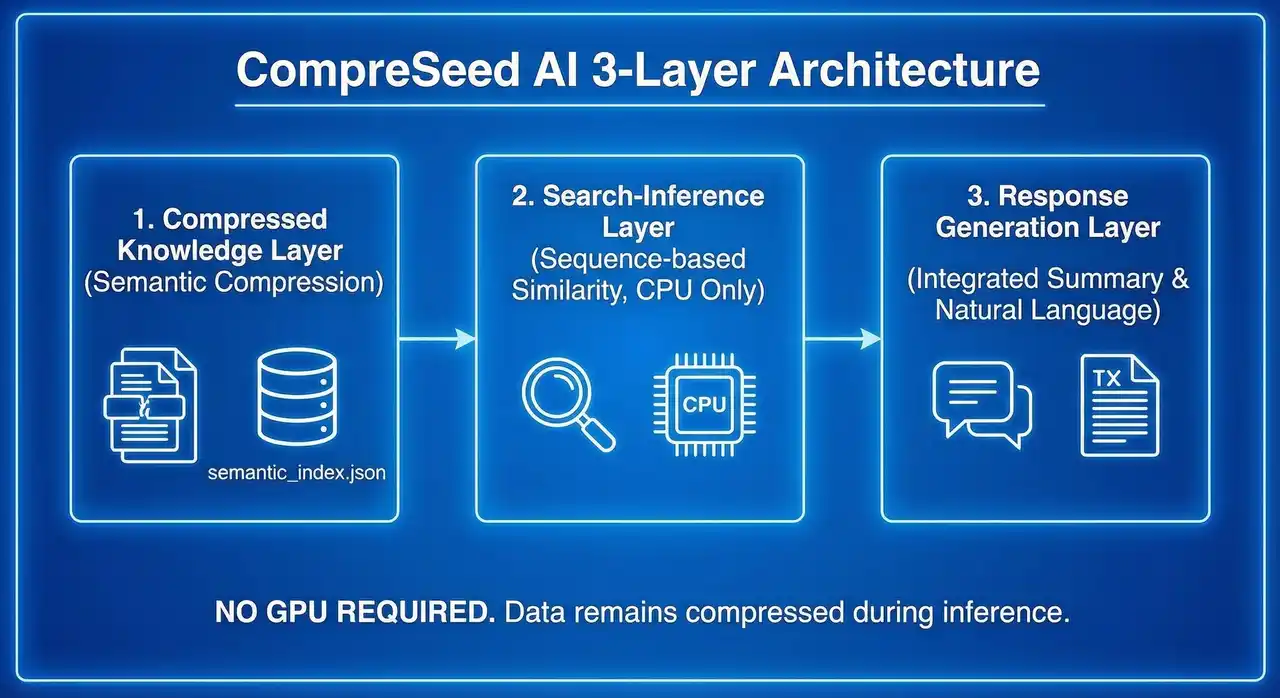
■ 3層アーキテクチャで高速・軽量化を実現
|
|
|
|
|
|
|
|
|
|
1. 圧縮知識層(Semantic Compression Layer)文書を意味単位で圧縮し、semantic_index.json に格納。 |
|
|
|
2. 検索・推論層(Search-Inference Layer)Sequence-based Similarity により、GPUなしで意味類似度を推定。 |
|
|
|
3. 応答生成層(Response Generation Layer)圧縮要約を統合し、自然文で回答生成。 |
|
※外部LLM(ChatGPT等)との接続も可能。 |
|
|
|
|
|
|
|
■ 従来技術との比較(FAISS・Embedding方式との対比) |
|
|
|
項目 |
ベクトル検索 (FAISS等) |
CompreSeed AI |
|
データ展開 |
必須 |
不要 |
|
必要GPU |
あり |
なし |
|
応答速度 |
2~4秒 |
0.2~0.8秒 |
|
メモリ消費 |
大 |
小(1/8) |
|
コスト |
高 |
1/50~1/70 |
|
知識更新 |
再学習必要 |
部分更新で可 |
|
|
|
|
GPU不要である点が最大の特徴です。 |
|
|
|
|
|
|
|
■ 応用領域(すぐに導入可能) |
|
|
|
自治体向け問い合わせAI |
|
教育:学習参考書型AI |
|
医療:症例知識検索 |
|
法務:条文・判例検索 |
|
企業内ナレッジ統合 |
|
オフライン環境下のAIシステム |
|
|
|
外部に情報を出せない現場で“ローカル大規模AI”を実現できます。 |
|
|
|
|
|
|
|
■ ホワイトペーパー公開(追試可能) |
|
今回、CompreSeed AI の技術詳細・再現手順をまとめた15ページのホワイトペーパーを公開しました。 |
|
|
|
内容例: |
|
圧縮推論アルゴリズム |
|
類似度計算モデル |
|
再構築手順 |
|
実機検証結果 |
|
API連携構造 |
|
評価方法 |
|
再現プロトコル(Replication Protocol) |
|
(ホワイトペーパーより抜粋:semantic_index構造の記載) |
|
|
|
|
|
|
|
■ 開発者コメント
|
|
「AIをもっと軽く、もっと扱いやすい技術にしたいと思い、GPUを使わずに大規模推論ができる“第三のAI構造”を作りました。今回、追試可能なホワイトペーパーも公開しました。研究者・企業の皆様に自由に検証していただきたいです。」 |
|
|
|
|
|
■ 今後の展開
|
|
特許出願済(国内) |
|
海外出願(PCT)を準備中 |
|
企業・自治体向け PoC を開始 |
|
API版 CompreSeed の公開準備 |
|
|
|
|
|
■ 会社概要
|
|
株式会社アイテック |
|
所在地:愛知県 |
|
事業内容:次世代AIの研究・開発 |
|
|
|
|
|
■ お問い合わせ
|
|
メール:info@xinse.jp |
|